13. Object Detection - two stage method(R-CNN, fast R-CNN, faster R-CNN)
지금까지 기초적인 부분과 튜닝에 대한 여러가지 기초지식을 배워왔다. 그리고 주로 이미지분류에 대한 공부를 많이해왔다.
이번에는 이미지 분류이외에도, 이미지에서 어떤 위치를 찾는 것에 대한 내용을 학습해보자.
크게, Localization, Detection, Segmentation이 있다.
3가지의 공통점은 모두 어떤 object에 대한 위치를 찾는 것이다.

차이점에 대해 살펴보자.
Localization : 고양이가 1마리 있다고 가정한다. 찾아서 박스를 친다.
Object Detection : 고양이나 강아지가 여러마리 있다고 가정한다. 찾아내서 박스를 친다.
Segmentation : 딕텍션과 비슷한데, 더 자세하게 픽셀단위로 보여준다.
이 3가지를 수행하려면, classification과 전혀다른 데이터셋이 필요하다.
지금까지 했던 classification의 dataset은 feature여러개 + label만 필요했다.
(feature1, feature2, ... , label)
하지만 Localization 의 dataset은 label + box의 x,y좌표, 가로,세로까지 필요하다
( C(label), x, y, w, h )
Detection의 경우, 박스가 여러개이므로, 저러한 dataset이 여러개 있을 것이다.
Segmentation의 경우, 박스의 x,y,w,h대신 , 14*14px이 있고, 거기에 0이면 고양이 없다 / 1이면 고양이 있다.의 형태가 될 것이다.



여기까지 이미지 위치찾는 것에 대해서,
1) 각 분야별로, 그에 맞는 가정이 있다.
2) 각 분야별로, 그에 맞는 dataset이 있다.
는 가정하에 진행된다. 이러한 dataset을 보유하기는 너무 힘들다. 공개되어있는 인터넷의 데이터셋을 사용하는 것에 크게 의존하고 있다.
여기서 Detection을 주로 다룰 것이다. Localization의 알고리즘은 거의다 Detection알고리즘으로 다 대체가 되었다고 한다. Segmentation은 아직 발전과제가 많이 남아있기 때문이다.
Localization 알고리즘
먼저, Localization이 어떻게 구성되었는지 알아보자.
앞서, Convolutional Layer의 Filter들은 각 이미지를 sliding window방식으로 좌상단에서부터 우하단까지 연산한다고 하였다.
Localization에서는 딥모델 전체가 Conv.Layer의 Filter들처럼, Sliding window방식으로 돌아다니면서, 강아지가 있는지 없는지 predict한다.
즉, 좌상단->우하단으로 딥러닝 알고리즘 통채로 1pixel씩 움직이면서 강아지가 있는지 없는지 predict하는 것이다.
움직이면서, '없다~ 없다~ 없다~' 하다가 강아지의 형체를 발견하면 predict의 확률을 높게준다.
마찬가지로, 아래칸에서 없다 없다 없다 하다가 있는 곳에서 predict의 확률을 높게 준다.


결과적으로, 곰이 있는 위치에는 확률를 높혀 노란색으로 / 중간정도는 보라색으로/ 없는 위치는 검은색으로
아래와 같이 표시된다.

이러한 Localization알고리즘(Overfeat 알고리즘)은 결과적으로는, 현재 쓰지 않지만 이러한 방식으로 작동하여 배울 점이 있다.
이 Overfeat알고리즘이 바로 이전시간에 다룬 (1,1) Convolution Layer로 발전했다는 것이다.
Fully-connected N.N. 대신 --> (1,1) Conv. Filter를 사용했을 때,
이미지를 더 큰 것을 집어넣을 수 있고, 잘 돌아간다.(FC layer는 input 이미지가 딱 정해진 것만 사용할 수 있었다.)
결과적으로 (1,1)이 나와야할 output이 ---> (2,2)로 나와서, 이것을 평균내는 것이 더 성능이 좋았다.

2015년까지는 이 Localization을 많이 사용하려 했었다. 왜냐하면 ResNet의 등장으로 인간의 분류능력을 뛰어넘으면서부터 ImageNet챌린지에서 2016년부터 classification경진대회를 없앴고 Classification+Localization대회를 만들었기 때문이다.
하지만, 2016~2017년 Localizaton경진대회에서 Detection알고리즘들이 우승을 해버렸기 때문에 지금은 Detection알고리즘이 메인이 되게 된 것이다.

Detection알고리즘
Localization과 달리, Detection은 기본적으로 한 이미지안에, 여러개의 Object가 있을 수 있고, Box도 여러개 칠 수 있다.

Detection알고리즘은 크게 2가지 방식이 있다.
- One-Stage Method : 속도가 빠름, ex> YOLO, SSD
- Two-stage Method : 정확도가 좋음, ex> R-CNN, Fast R-CNN, Faster R-CNN


먼저 나온 것은 Two stage Method이고, 최근에 나온 것이 One stage Method이다. One Stage 방식이 더 깔끔하고 구현도 쉽다.
실무에서도 One-Stage를 속도때문에 훨씬 더 많이 쓴다고 한다.
특히, 자율주행자동차에서는 realtime으로 예측해야하므로 실행속도가 중요하다. 그래서 One stage를 많이 쓰고, 발전 중이다.
Detection - Two Stage Method - R-CNN
Two stage method는 지금껏 학습한 것들이 순서대로 연결되어있으므로, 헤깔릴 수 있다. 그래서 순서를 인지하면서 학습해야한다.
먼저, 13년도에 출현한 R-CNN이다.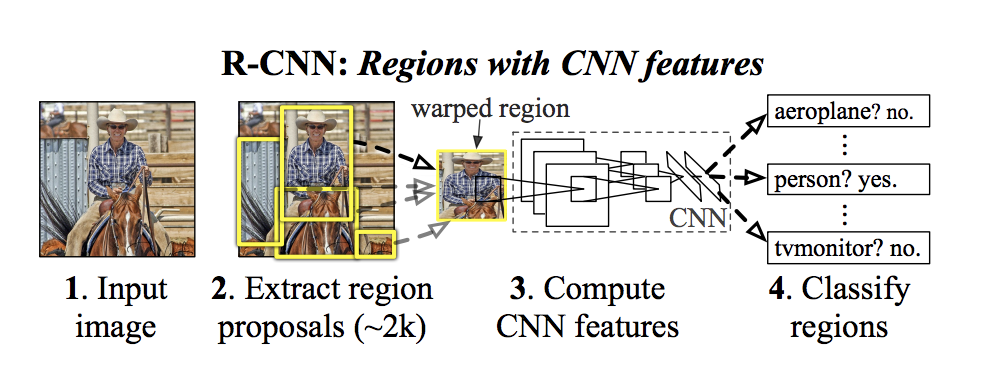
이 R-CNN이 two stage method인 이유는 기존알고리즘으로 먼저 찾고+ 딥러닝으로 다시 찾는 것, 2stage로 나눠져 있기 때문이다.

- 먼저, image classification 모델이 있다는 전제하에 시작한다. 그것을 transfer learning할 것이다.
- 13년에 나온 2 stage method의 시초라 할 수 있는 R-CNN은, 12년도에 사용되었던 AlexNet을 이미지classification 모델로 사용했을 것이다. - 가져온 classification 모델을 2개로 복사한다.
1) classification 모델 : 이미지에 고양이/강아지가 있냐 없냐를 판단하는 모델 -> classification을 맞춰야한다.
- 기존 classification모델은 1000개의 카테고리를 맞추는 imageNet챌린지용이었다.
- 너무 많으므로 기존 모델의 output Layer만 바꿔서 1000개
-> output(카테고리) 20개+(아무것도 detection못한 경우인 background)1 = 21개로 바꾼다.
2) Regression 모델 : Box를 쳐주는 모델 -> x,y,w,h를 맞춰야한다.
3) 2 모델을 따로 predict한다.
- 하지만 이 것만으로는 성능이 잘 안나와서 기존의 Detection알고리즘을 사용에 box후보군을 잘라서 넣어줄 것이다. - 기존의 Obejct detection 알고리즘 중 가장 성능좋은 Selective Search 알고리즘(region proposal)을 2개의 모델 앞에 적용한다.
- Localization처럼 sliding window방식은 아니지만, 전체 이미지 중 box쳐질만한 이미지의 일부분을 잘라주는 기존 Detection알고리즘이다.
- Selective search는 하나의 이미지에서 2000개의 box후보군을 잘라준다. - Selective Search(region proposal)로 쪼개진 이미지의 일부분을 CNN인 Classification모델 / Regression모델에 각각 넣어준다.
(참고로 SVM은, 서포트 백터 머신으로, loss용으로 쓰는 알고리즘 중에 cross-entropy / SVM이 있는데 SVM은 안쓴다)
결과적으로, VOC 2010 test 데이터셋(20개 카테고리)이 사용된 이미지넷챌린지 13년도 경진대회에서
기존 알고리즘들 + Localization알고리즘인 OverFeat를 사용하는 것보다
Detection알고리즘인 R-CNN을 사용하는 것이 성능이 월등히 좋았다.
참고로 mAP(mean Average Precision)는 예측한 Box와 정답Box의 일치정도라고 보면 된다.
참고)http://better-today.tistory.com/3?category=699736


R-CNN의 단점은 복잡+느린 것이다. 기본적으로 3개의 모델이 필요했다
- pre-trained된 classification모델
- 그것의 output개수를 고친 classification모델
- 그것으로 BoundBox의 x,y,w,h를 맞추는 Regression모델
- 이미지를 input할 때, Selective search로 후보Box들을 잘라내기 위해 2000번 자를 때, 속도가 너무 오래 걸린다. 그만큼 용량도 많이 필요한다. (이미지넷챌린지 이미지는 압축해도 60GB -> 한 이미지당 2000번 쪼개서 만드니 60 * 2000 GB..)
사실 Selective Search로 자른 2000장의 새로운 후보이미지들은 너무 용량이 크므로, 하드에 저장했다가 다시 꺼내서 쓴다고 한다. 용량 뿐만 아니라 속도도 어마어마하게 느려져서 개선의 여지가 필요했다.
즉, 결과적으로 모델을 줄이고(3->1) + 용량을 줄여 속도를 빠르게(Selective search의 순서바꿈) 하는 새로운 Detection알고리즘이 필요했다.
Detection - Two stage method - fast R-CNN

R-CNN과의 차이점은
R-CNN : 이미지를 먼저 Selective search로 2000개로 쪼갠것을 --> CNN에 넣느냐
Fast R-CNN : 이미지 1개만 CNN에 넣고 --> 나온 결과물을 Selective search로 2000번 쪼개느냐의 순서차이이다.
여기서 , CNN에서 나온 결과물(output feature)은 , RGB픽셀로 구성된 이미지가 아니라서 바로 Selective search에 들어가 쪼개질 수 없다.
그 output은 새롭게 뽑혀진 크고 작은 output feature일 뿐이다.
그래서 input image를
- CNN에 집어 넣기전에 이미지에 selective search(region proposal)을 먼저 돌려, 이미지를 어떻게 자를지에 대한 x,y,w.h 좌표만 구해놓는다. 그 좌표를 가지고 있는다.
- 이제 input image를 CNN에 넣으면 output feature(feature map)가 나온다.
- output feature는 이미지가 아니라서 selective search에 못넣었었다. 그러나
CNN을 통해 나온 output feature가, intput image에 비해 얼마나 작아졌는지 계산할 수 있다.
예를 들어)
(3,3) Convolutional Layer에 zeropadding을 넣었다면, input과 output 사이즈가 똑같았다.
여기서 maxpooling이 들어가면 가로세로 사이즈가 절반으로 줄었다.
이런식으로 CNN의 구조를 고려하여, input image의 사이즈가 얼마나 줄었는지 알 수 있다.
즉, output feature(feature map)의 사이즈를 유추할 수 있다는 것이다. - 그 유추한 계산을 바탕으로 + 1번에서 구해놓은 잘라야할 x,y,w,h좌표를 이용해 output feature를 2000번 자르면 되는 것이다.

이제 R-CNN에서 3개나 되었던 모델을 어떻게 줄여보자.
R-CNN에서는 Transfer Learning(CNN)모델을 --> Reg모델 / Classification모델 2개로 나누어서 따로 튜닝했었다.
Fast R-CNN에서는 Transfer Learning(CNN)모델을
--> 다시 1개의 모델로 만든 다음, output Layer만 2개로 나누어서, 따로 loss function구하고 따로 backpropagation하여 구한다.
--> 1개의 모델을 output만 2개로 나눈 효과는, classification와 regression의 backpropagation구할 때, 서로 긍정적인 효과를 미쳐 성능이 더 좋아진다 것이다.

그림에서 보면, Fully-Connected가 있다. 아직 13년도여서 (1,1) Convolution Layer에 대한 지식이 없었기 때문이다.
Fully-Connected의 단점은 input 되는 image의 사이즈가 서로 똑같아야한다는 것이다.
바로 직선에서 Selective search로 제각각 2000조각 난 output feature의 사이즈를 resizing해야만 할 것이다.
하지만 Output feature(feature map)은 이미지가 아니라서 resizing을 할 수 없다.
일반적인 R-CNN은 처음 Selecitve search시, 이미지를 크롭해준 것이기 때문에 resizing이 바로 가능했다.
Fast R-CNN은 resize해줘야할 것이 이미지가 아니라, output feature인 문제가 발생하는데,,,
이러한 문제를 어떻게 해결 했을까?
바로 Roi pooling이라는 것을 개발해서 해결했다. Max pooling으로 사이즈를 절반으로 줄이는 것과 비슷한 개념이다.
Selective Search(region proposla)에 의해 제각각으로 잘린 output feature(feature map)을 같은 사이즈로 변환하여
Fully-connected에 넣어주는 방식이다.
좀 더 구체적으로 예를 들면 (2,2) Maxpooling을 하면 사이즈가 절반으로 줄어들 것이다. 만약, (3,3) Maxpooling하면 그냥 퉁치고 넘어간다고 한다. 이것과 비슷한 것이 RoI pooling이다.

결과적으로 R-CNN보다, Fast R-CNN이 얼마나 빨라지는지 보자.

Train속도는 84시간 -> 8시간으로 줄었고, test속도는 49초 -> 2초로 준다.
(빨간색 그래프는 속도가 느린 Selective search( region proposal)을 뺐을 때 결과)
그러나, 요즘은 테스트시 2초도 느린편이다.. 예를 들어, 자율주행자동차에서 realtime으로 안되면,, 사고가 발생할 수 도 있을 것이다.
그래서 fast R-CNN의 단점인, 가장 성능이 느린 기존 알고리즘인 Selective search(Region proposal)하는 부분도 딥러닝으로 만들 수 있다.
Detection - Two stage method - faster R-CNN
fast R-CNN 중 전통적인 알고리즘인 Selective Search(Region proposal)부분을 딥러닝으로 바꾼 것을 RPN(Region Proposal Network)라 한다.
즉, 이 CNN기반의 미니 CNN인 Region Proposal Network가 이미지-> CNN 을 거쳐 나온 -> output feature(feature map)를 잘라준다.
RPN안에는 Convolution Layer에 심지어 fully-connected Layer도 존재한다.
RPN의 Convolution N.N.이 output feature를 sliding window방식으로 돌면서 연산후 classification 과 Regression연산까지 한다.
forward / backward propagation -> weight 업데이트 과정을 거치면 ---> Selective search를 대체하여 이미지를 2000box 조각낸다.
즉, CNN기반의 RPN이 sliding window방식으로 box를 찾는 역활한다.
이 때, box를 찾는 과정에서, 어떤 object는 가로가 길고, 어떤 object는 세로가 길어서, sliding window가 꼭 정사각형이 아니라 직사각형 형태로 도는 것이 유리할 수 있다. 이러한 여러형태의 sliding window를 anchor box라 한다.
그래서 RPN에서는 output feature인 feature map을 도는 여러개의 anchor box를 운영하고, 공식문서에서는 아래 형태의 4개의 anchor box를 운영한다.
즉, CNN의 필터 대신, RPN는 4개의 anchor box를 사용하여, 4개 따로 forward/backward하면서 training하여, 2000조각 낼 부분을 predict한다.


참고로 4개의 anchor box는, 개발자마다 설정(configuration이 가능하다)

요약 )
- image를 CNN에 집어넣는다.
- CNN에서 나온 output feature( feature map )을 Selective Search를 대체하는
Region Proposal Network에 집어넣어 classification 과 box얼마나 쳐야하는지를 따로 return받는다. - RoI pooling을 이용하여 box크기를 fully-connected에 넣을 수 있게 resizing해준다.
- fast R-CNN과 동일하게 해준다.
1개의 모델에 꼬다리만 classifcation / regression을 따로 만들어 loss2개, weight업데이트도 2개 따로하여
classification / regression(box위치)를 predict한다.
결과적으로 test시
R-CNN : 49초 ----------->Region Proposal(Selective Search)의 순서를 바꾸고, 모델 2개를 1개의 모델로 통합(꼬다리만 2개로)
Fast R-CNN : 2.3초 ---->Region Proposal(Selective Search)를 Region Proposal Network(CNN)으로 대체-->
Faster R-CNN : 0.2초

One-Stage-Method는 속도...
정확도를 위해서라면 우리는 Two-stage-Method인 Faster R-CNN을 쓰면 된다.
'머신러닝 & 딥러닝 > 딥러닝 - Image classification' 카테고리의 다른 글
| 15. Batch size & Batch Norm (0) | 2018.08.19 |
|---|---|
| 14. Regularization (0) | 2018.08.19 |
| 12. Data Preprocessing & Augmentation (0) | 2018.08.02 |
| 11. Optimization - local optima / plateau / zigzag현상의 등장 (1) | 2018.08.02 |
| 10. transfer learning (0) | 2018.07.31 |